





In Part 7, we introduced embedding similarity-based methods as one of the two major families of unsupervised deep learning approaches for visual defect detection. At a conceptual level, these methods detect anomalies by measuring how dissimilar a sample’s learned feature representation is from normal data.
Embedding Similarity Based Algorithms for Visual Defect Detection
In practice, however, this idea has been realized through a wide range of algorithmic designs. These algorithms differ in:
- How embeddings are extracted
- At what spatial scale similarity is measured
- How normal reference representations are stored
- How anomaly scores are computed
This section surveys the main algorithmic patterns that fall under the embedding similarity paradigm and explains how they operate in real inspection systems.
Embedding Similarity for Defect Detection, Detect What Doesn’t Belong.
AI-powered embedding similarity methods compare visual patterns to identify subtle defects and anomalies with high precision. Enable flexible, scalable inspection systems that adapt quickly to new products and evolving manufacturing conditions.
Core Workflow of Embedding Similarity Based Detection
Despite their variations, most embedding similarity-based algorithms follow a common pipeline:
- Extract deep feature embeddings from images or image patches
- Build a reference representation of normal embeddings
- Compare test embeddings against the normal reference
- Assign anomaly scores based on similarity or distance
- Aggregate local scores into image-level decisions
The differences between algorithms lie primarily in steps 1–4.
Patch-Based Embedding Methods
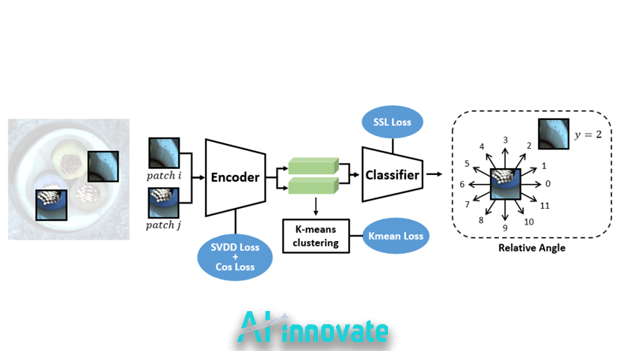
Motivation: Localizing Subtle Defects
Many industrial defects are local rather than global: scratches, pits, cracks, or texture irregularities that affect only small regions of an image. Patch-based methods address this by operating on local image patches instead of whole images.
How Patch-Based Methods Work
In these approaches:
- Images are divided into overlapping or non-overlapping patches
- Each patch is passed through a deep network to extract an embedding
- Normal patch embeddings form a reference distribution
- Test patches are scored based on similarity to normal patches
The final anomaly map highlights regions whose embeddings deviate from normal patterns.
Practical Strengths
Patch-based methods are particularly effective for:
- Texture-based defects
- High-resolution images
- Fine-grained defect localization
They also align well with convolutional architectures, which naturally produce spatial feature maps.
Nearest-Neighbor–Based Similarity
Distance as an Anomaly Signal
A widely used strategy in embedding-based detection is nearest-neighbor comparison. Here, anomaly scores are derived from the distance between a test embedding and its closest normal embedding.
Typical distance metrics include:
- Euclidean distance
- Cosine distance
- Mahalanobis distance
A large distance indicates that the test sample lies far from the normal data manifold.
Memory-Based Normal Representations
In many algorithms, normal embeddings are stored explicitly in a memory bank. During inference:
- Each test embedding is compared against stored normal embeddings
- The minimum or average distance is used as the anomaly score
This design avoids explicit model training for defect classification and instead relies on similarity search in feature space.
Trade-Offs
Nearest-neighbor approaches offer:
- Strong performance on unseen defect types
- Simple conceptual interpretation
However, they introduce:
- High memory consumption
- Computational cost for large reference sets
These trade-offs become important in large-scale industrial deployments.
Multi-Scale Embedding Strategies
Why Scale Matters
Defects appear at different spatial scales:
- Large structural defects
- Medium-scale shape deviations
- Fine-grained texture anomalies
Single-scale embeddings may fail to capture this diversity.
Multi-Layer Feature Extraction
Many algorithms address this by extracting embeddings from multiple layers of a deep network:
- Early layers capture fine textures
- Deeper layers capture semantic structure
These multi-scale embeddings are either:
- Concatenated
- Compared independently
- Aggregated hierarchically
This improves robustness across a wide range of defect types.
Pretrained Feature Extractors
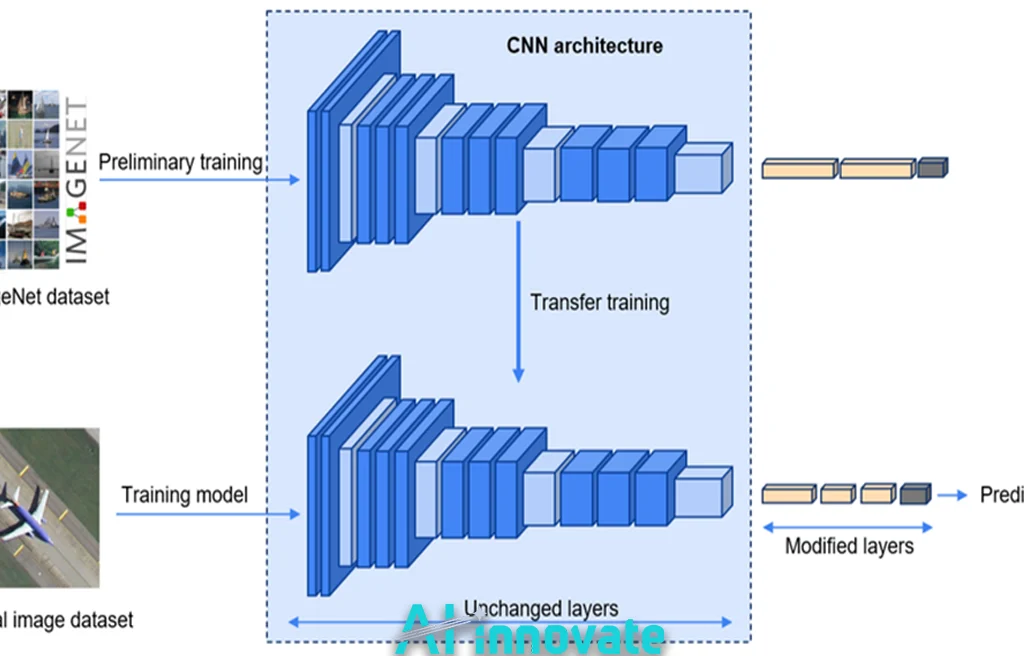
A defining characteristic of many embedding similarity-based methods is the use of pretrained deep networks as feature extractors.
Rather than training networks from scratch, these methods leverage models pretrained on large-scale datasets to obtain:
- General-purpose visual representations
- Strong texture and shape sensitivity
- Reduced training requirements
This transfer learning paradigm significantly lowers the barrier to deploying defect detection systems.
Statistical Modeling in Embedding Space
Some methods go beyond nearest-neighbor distance and build statistical models of normal embeddings.
Examples include:
- Modeling normal embeddings as Gaussian distributions
- Estimating covariance structures
- Computing likelihood-based anomaly scores
These approaches treat defect detection as a density estimation problem in feature space, offering more principled anomaly scoring in some settings.
Aggregation from Patch-Level to Image-Level Decisions
While embedding similarity is often computed locally, industrial inspection usually requires image-level decisions.
Common aggregation strategies include:
- Maximum anomaly score across patches
- Average or weighted average scoring
- Thresholding of anomaly maps
The choice of aggregation strategy affects sensitivity to small vs. large defects and influences false positive rates.
Why Embedding Similarity Methods Became So Popular
Embedding similarity-based methods have gained traction because they:
- Allign well with unsupervised learning constraints
- Generalize to unseen defects
- Provide spatial localization
- Leverage pretrained deep networks
They offer a practical compromise between flexibility and performance, making them attractive for real-world industrial inspection.
Emerging Variations and Hybrid Designs
Recent research has explored hybrid designs that:
- Combine reconstruction and embedding similarity
- Use compact memory representations
- Introduce adaptive similarity thresholds
These variations aim to improve efficiency and robustness while preserving the core similarity-based philosophy.
Setting the Stage for Critical Evaluation
Despite their strengths, embedding similarity-based methods are not without limitations. Their performance depends on:
- Feature extractor choice
- Memory size and representation
- Distance metrics and thresholds
- Sensitivity to distribution shifts
Understanding these limitations is essential for responsible deployment.
Bridging to Part 9
Embedding similarity-based algorithms represent one of the most powerful and widely adopted families of unsupervised defect detection methods. However, their real-world behavior reveals important weaknesses and failure modes that are often overlooked in high-level discussions.
In Part 9, we will critically examine:
- Scalability and memory constraints
- Sensitivity to domain shift
- Threshold selection challenges
- Failure cases in industrial environments
By understanding not only how these algorithms work but also where they break we move closer to designing robust, production-ready defect detection systems.
Confused About Where to Start with AI?
Our specialists help you identify the right AI approach based on your process, data, and goals.










