





In Part 6, we introduced deep learning for visual defect detection and explained why many industrial environments cannot rely solely on supervised approaches. In practice, manufacturers often face a fundamental constraint: defective samples are rare, diverse, and difficult to label, while normal samples are abundant.
Unsupervised Deep Learning Methods for Visual Defect Detection
This reality makes unsupervised defect detection especially attractive. Instead of learning what defects look like, unsupervised methods focus on learning what “normal” looks like and treating deviations from normality as potential defects.
In this section, we examine the two dominant paradigms of unsupervised deep learning for visual defect detection:
- Reconstruction-based methods
- Embedding similarity-based methods
Understanding the conceptual differences between these two families is essential for selecting and designing effective inspection systems.
Unsupervised Deep Learning for Defect Detection Discover the Unknown.
Leverage unsupervised deep learning to identify anomalies and visual defects without labeled data. Detect previously unseen issues, adapt to changing production conditions, and maintain high-quality standards with intelligent, self-learning inspection systems.
The Core Idea of Unsupervised Defect Detection
Unsupervised defect detection reframes inspection as an anomaly detection problem.
Rather than asking:
Which defect class does this sample belong to?
the system asks:
How much does this sample deviate from what I have learned as normal?
This shift aligns naturally with industrial inspection, where:
- Normal production dominates the data distribution
- Defects are unpredictable and evolving
- New defect types may appear over time
The challenge lies in how normality is learned and how deviation is measured..
Two Fundamental Views of “Normality”
Unsupervised methods differ primarily in how they represent normal data:
- Reconstruction-based methods model normality by learning to reproduce normal samples.
- Embedding similarity-based methods model normality by learning a feature space where normal samples cluster tightly together.
Each approach defines anomalies in a fundamentally different way, leading to distinct strengths and limitations.
Reconstruction-Based Methods
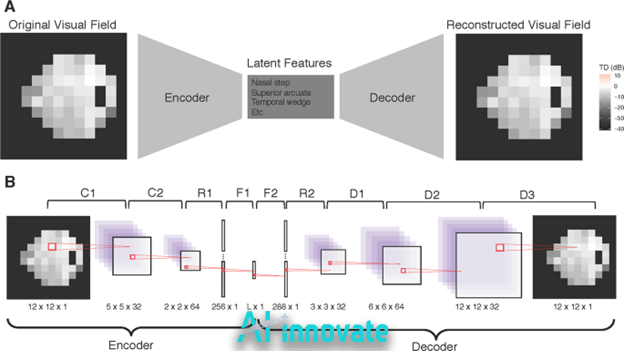
Core Principle
Reconstruction-based methods assume that a model trained only on normal data will:
- Accurately reconstruct normal samples
- Fail to reconstruct abnormal or defective samples
Defects are detected by measuring reconstruction error the difference between the input image and its reconstructed output.
Typical Architectures
Common reconstruction-based models include:
- Autoencoders (AEs)
- Convolutional autoencoders
- Variational autoencoders (VAEs)
- Encoder–decoder architectures with skip connections
These models compress input images into a latent representation and then attempt to reconstruct the original image.
This Topic might also interest you :
Why Reconstruction Works (and When It Doesn’t)
Reconstruction-based approaches work best when:
- Normal appearance is highly regular
- Defects introduce clear structural disruption
- Image complexity is moderate
However, in practice, deep autoencoders can become too powerful. When trained extensively, they may learn to reconstruct defective regions as well, thereby reducing reconstruction error and masking defects.
This phenomenon is especially problematic for:
- Subtle texture defects
- Small local anomalies
- High-resolution images
As a result, reconstruction error does not always correlate well with defect severity.
Strengths and Limitations
Strengths:
- Conceptually intuitive
- End-to-end training
- No defect labels required
Limitations:
- Poor localization for subtle defects
- Risk of over-generalization
- Sensitivity to reconstruction loss design
These limitations have motivated alternative unsupervised strategies.
Embedding Similarity-Based Methods
Core Principle
Embedding similarity-based methods take a different perspective. Instead of reconstructing images, they:
- Map images (or image patches) into a feature embedding space
- Learn the distribution of embeddings for normal data
- Detect anomalies as outliers or low-similarity samples in that space
In this framework, defect detection becomes a distance or similarity problem, not a reconstruction problem.
Learning Normality in Feature Space
These methods rely on deep networks—often pretrained or partially trained—to extract semantic and texture-rich features.
Normal samples form a compact manifold in embedding space. Defects manifest as:
• Large distances from nearest normal embeddings
• Low similarity scores
• Regions that do not align with learned feature distributions
This approach is particularly effective for detecting local, subtle, and texture-based anomalies.
Conceptual Advantages Over Reconstruction
Embedding-based methods address several weaknesses of reconstruction-based approaches:
- They do not require pixel-level reconstruction
- They are less prone to “reconstructing defects”
- They offer better localization via patch-wise embeddings
As a result, embedding similarity-based methods have gained significant attention in recent research and industrial applications.
- Read Also:
A Conceptual Comparison of the Two Paradigms
Aspect | Reconstruction-Based | Embedding Similarity-Based |
Normality Model | Ability to reconstruct | Compactness in feature space |
Anomaly Signal | Reconstruction error | Distance / similarity |
Localization | Often coarse | Often fine-grained |
Sensitivity to Subtle Defects | Limited | Strong |
Risk of Over-Generalization | High | Lower |
This comparison highlights why many modern systems favor embedding-based approaches, especially for complex visual inspection tasks.
Choosing Between the Two in Practice
The choice between reconstruction-based and embedding similarity-based methods depends on:
- Defect characteristics
- Image resolution and complexity
- Need for localization accuracy
- Computational constraints
In some systems, hybrid approaches combine both ideas to leverage their complementary strengths.
Why Embedding Similarity Deserves Deeper Attention
While both paradigms are unsupervised, embedding similarity-based methods represent a more flexible and scalable foundation for industrial defect detection.
They:
- Integrate naturally with pretrained deep networks
- Scale well to high-resolution images
- Generalize better across defect types
For these reasons, a growing body of research focuses specifically on how embeddings are constructed, compared, and interpreted for defect detection.
Bridging to Part 8
Unsupervised deep learning offers powerful tools for visual defect detection, but not all unsupervised methods behave the same. The distinction between reconstruction-based and embedding similarity-based approaches is fundamental to understanding their performance and limitations.
In Part 8, we will focus exclusively on:
- Different embedding similarity-based methods
- How embeddings are extracted and compared
- Design choices that affect detection accuracy and robustness
- Practical examples of similarity-driven defect detection
By examining these methods in detail, we move closer to answering a central question of this series:
How can machines reliably detect defects they have never seen before?
Confused About Where to Start with AI?
Our specialists help you identify the right AI approach based on your process, data, and goals.










