






In Part 8, we explored embedding similarity–based algorithms and explained why they have become a dominant paradigm in automated visual inspection. Their ability to generalize to unseen defects, operate without defect labels, and localize anomalies has made them attractive for real-world manufacturing.
Limitations and Failure Modes of Embedding Similarity Based Defect Detection
However, strong performance in benchmarks does not guarantee robustness in production. When deployed at scale, embedding-based systems reveal important weaknesses that can limit reliability, increase operational cost, and erode trust in automated inspection.
This section critically examines the structural limitations and failure modes of embedding similarity based methods not to dismiss them, but to understand where they break and why.
Understanding the Limits of Embedding-Based , Defect Detection.
Explore the challenges and failure modes of embedding similarity–based defect detection, from data bias to domain drift. Learn where these methods struggle and how informed system design improves reliability, robustness, and real-world performance.
Dependence on Feature Extractor Quality
At the heart of every embedding-based method lies a feature extractor, typically a deep neural network.
Why This Is a Vulnerability
Embedding similarity methods assume that:
- Normal and defective samples are separable in feature space
- Extracted embeddings capture defect-relevant information
In practice, this assumption heavily depends on:
- The architecture of the feature extractor
- The data used for pretraining
- The layer(s) from which features are taken
If the feature extractor fails to encode subtle defect cues especially texture-level or material-specific variations no similarity metric can recover the missing information.
As a result, performance may degrade sharply when:
- Defects are visually subtle
- Materials differ from pretraining data
- Defect cues are domain-specific
Sensitivity to Domain Shift
One of the most critical challenges in industrial deployment is domain shift—the mismatch between training conditions and real-world operation.
Common Sources of Domain Shift
- Changes in lighting conditions
- Camera replacement or reconfiguration
- Material batch variations
- Process drift over time
Embedding similarity–based methods often assume that normal data distribution remains stable. When this assumption is violated, normal samples may appear anomalous in feature space, leading to false positives.
In production environments, even small shifts can accumulate into significant inspection instability.
Memory and Scalability Constraints
Many embedding-based algorithms rely on memory banks that store embeddings of normal samples.
Why This Becomes a Problem
As production volume grows:
- Memory requirements increase linearly
- Nearest-neighbor search becomes computationally expensive
- Latency constraints tighten
In high-resolution, patch-based systems, the number of stored embeddings can reach millions, making real-time defect analysis challenging without aggressive approximation or pruning strategies.
This introduces trade-offs between:
- Detection accuracy
- Memory footprint
- Inference speed
Threshold Selection and Calibration Challenges
Embedding similarity produces continuous anomaly scores, but industrial inspection requires binary decisions: pass or fail.
The Threshold Problem
Choosing a similarity threshold is notoriously difficult:
- Too strict → excessive false positives
- Too lenient → missed defects
Thresholds that work well during validation may fail in production due to:
- Distribution drift
- Rare but acceptable variations
- Changes in defect prevalence
Moreover, threshold tuning often requires manual intervention and domain expertise, partially reintroducing the human dependency that automation aimed to remove.
Ambiguity Between Anomalies and Acceptable Variations
Embedding similarity methods detect difference, not necessarily defect.
In many manufacturing processes:
- Acceptable variations exist within tolerance
- Visual diversity does not imply functional failure
Embedding-based systems may flag:
- Benign texture changes
- Cosmetic variations
- Process noise
as anomalies, even though they are acceptable from a quality standpoint. This leads to over-detection and unnecessary rejects.
Weakness in Global Structural Defects
Patch-based embedding methods excel at local anomalies, but they can struggle with global or structural defects, such as:
- Missing large components
- Incorrect assembly configuration
- Global deformation
Because similarity is often computed locally, global context may be underrepresented, causing certain defect types to slip through undetected.
Limited Interpretability and Debuggability
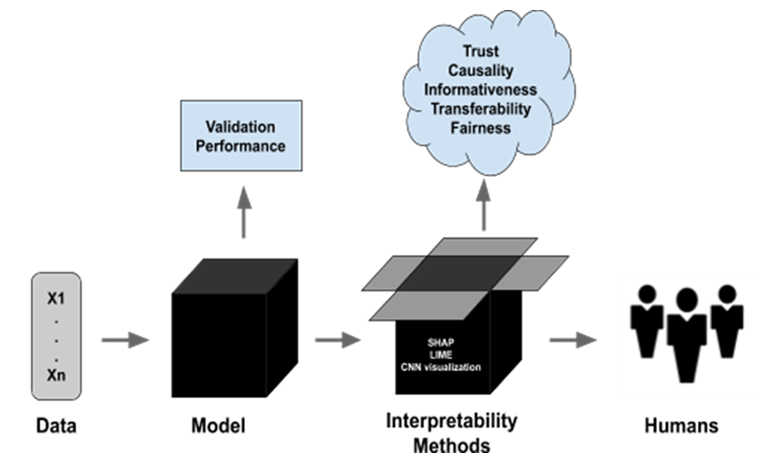
While more interpretable than some deep classifiers, embedding similarity–based methods still suffer from:
- Opaque feature representations
- Non-intuitive distance metrics
- Difficulty explaining why a sample is anomalous
This complicates:
- Root-cause analysis
- System validation
- Regulatory compliance
In industrial environments, lack of explainability can be as problematic as low accuracy.
Sensitivity to Reference Set Quality
Embedding similarity assumes that the reference set of normal embeddings is:
- Representative
- Clean
- Comprehensive
In practice:
- Normal datasets may contain undetected defects
- Rare normal patterns may be underrepresented
- Data collection biases may exist
These issues can distort the learned normal manifold, leading to unreliable anomaly scoring.
Maintenance Burden Over Time
Although unsupervised methods reduce labeling effort, they do not eliminate maintenance.
Over time, embedding-based systems often require:
- Reference set updates
- Feature extractor reevaluation
- Threshold recalibration
Without careful monitoring, performance degradation may go unnoticed until significant quality issues arise.
Summary of Key Limitations
Challenge | Impact |
Feature extractor dependence | Missed subtle defects |
Domain shift sensitivity | False positives |
Memory and compute cost | Scalability limits |
Threshold selection | Operational instability |
Over-detection | Increased reject rates |
Limited explainability | Reduced trust |
Maintenance needs | Ongoing engineering effort |
These limitations do not negate the value of embedding similarity–based methods but they clearly define where caution is required.
Why These Limitations Matter for the Future
As industries move toward fully autonomous quality control, the weaknesses of current methods become more visible. High false-positive rates, fragile calibration, and scalability constraints limit how far embedding-based systems can be pushed without architectural evolution.
Recognizing these limitations is not a step backward it is a prerequisite for progress.
Bridging to the Final Part
Embedding similarity–based algorithms represent a major milestone in unsupervised defect detection. Yet, their limitations highlight a deeper truth:
Industrial defect detection is not a solved problem it is an evolving one.
In Part 10, the final section of this series, we will look forward and explore:
- Emerging trends in industrial defect detection
- Hybrid and adaptive inspection systems
- The role of foundation models and self-supervision
- How future systems may overcome today’s limitations
Only by understanding both the strengths and weaknesses of current approaches can we design the next generation of intelligent inspection systems.
Confused About Where to Start with AI?
Our specialists help you identify the right AI approach based on your process, data, and goals.










